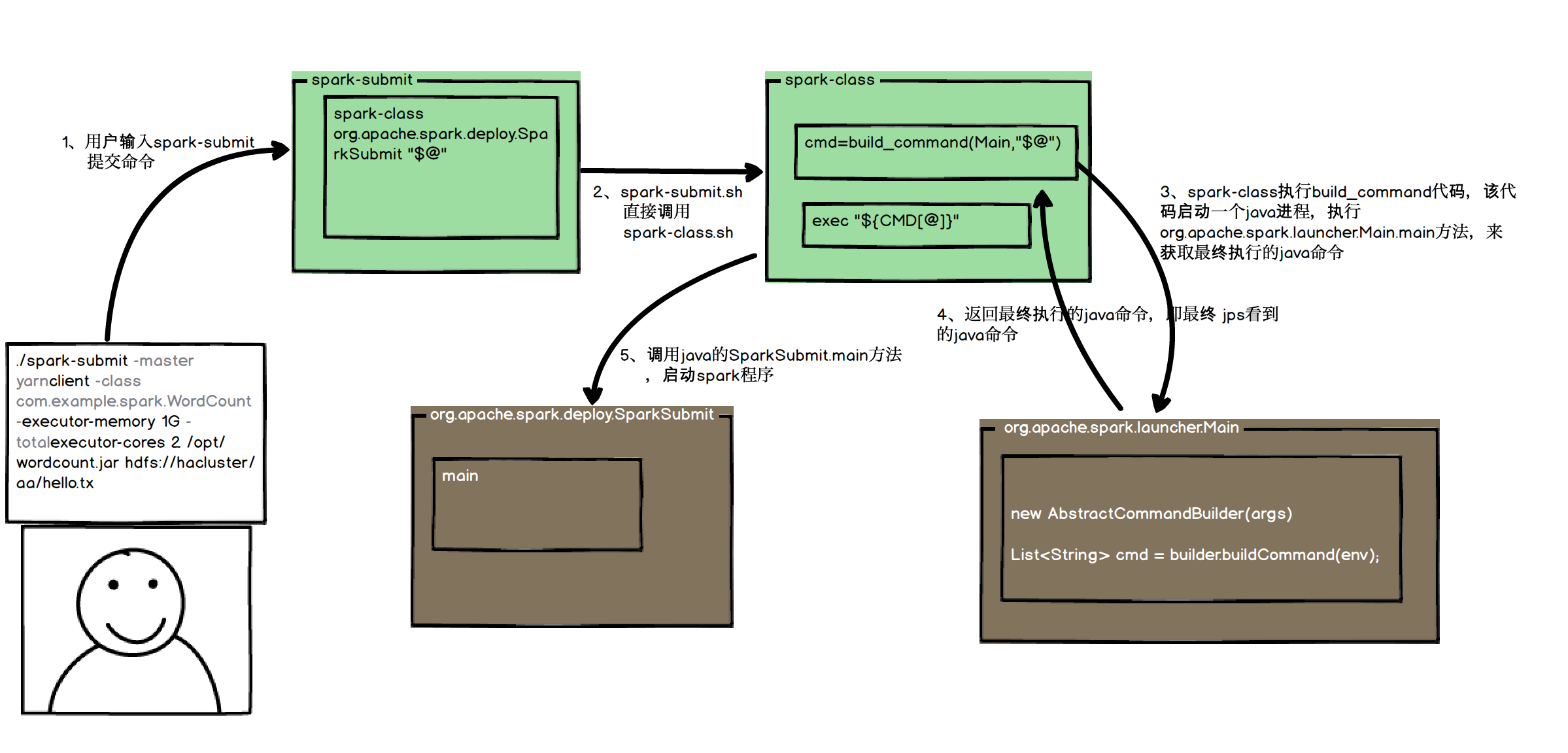
# 开启模块,使用代理 go env -w GO111MODULE=on go env -w GOPROXY=https://goproxy.cn,direct
#编译服务端 linux 64位 服务器 GOOS=linux GOARCH=amd64 make release-server
# 编译客户端 64位windows客户端: GOOS=windows GOARCH=amd64 make release-client #编译客户端 mac 64 位 客户端 GOOS=darwin GOARCH=amd64 make release-client #编译客户端 linux 64 位客户端 GOOS=linux GOARCH=amd64 make release-client
begin; SELECT*from city where id = "1" lock in share mode;
然后在另一个查询窗口中,对id为1的数据进行更新
1 2 3 4
update city set name="666" where id ="1"; 此时,操作界面进入了卡顿状态,过几秒后,也提示错误信息 [SQL]update city set name="666" where id ="1"; [Err] 1205- Lock wait timeout exceeded; try restarting transaction
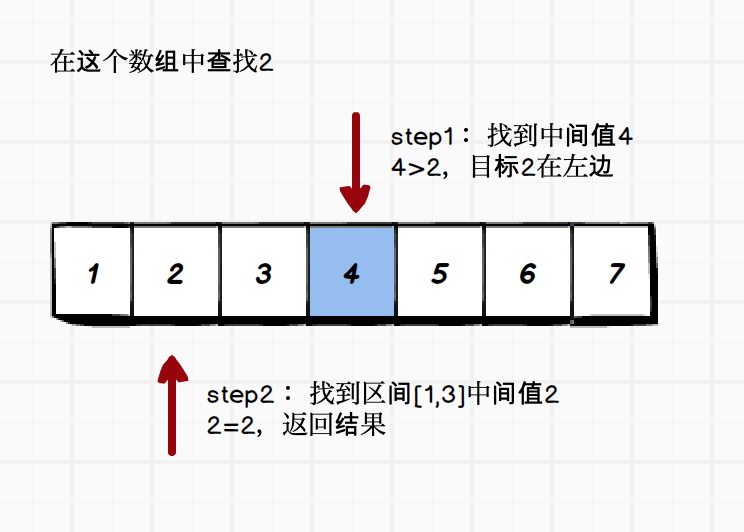
# 左边界 int mid=(l+r)/2; int mid=(l+r)>>1; int mid=l+(r-l)/2; int mid=l+((r-l)>>1); # 右边界 int mid=(l+r+1)/2; int mid=(l+r+1)>>1; int mid=l+(r-l+1)/2; int mid=l+((r-l+1)>>1);
if (isWindows()) { System.out.println(prepareWindowsCommand(cmd, env)); } else { // In bash, use NULL as the arg separator since it cannot be used in an argument. List<String> bashCmd = prepareBashCommand(cmd, env); for (String c : bashCmd) { System.out.print(c); System.out.print('\0'); } }